Propaganda
Você acredita na ideia de que, uma vez que algo é publicado na Internet, é publicado para sempre? Bem, hoje vamos dissipar esse mito.
A verdade é que, em muitos casos, é bem possível erradicar informações da Internet. Claro, há um registro de páginas da web que foram excluídas se você pesquisar no Wayback Machine, certo? Sim, absolutamente. No Wayback Machine, existem registros de páginas da web que remontam a muitos anos - páginas que você não encontrará em uma pesquisa no Google porque a página da web não existe mais. Alguém o excluiu ou o site foi encerrado.
Então, não há como fugir disso, certo? A informação será gravada para sempre na pedra da Internet, lá por gerações para ver? Bem, não exatamente.
A verdade é que, embora possa ser difícil ou impossível eliminar as principais notícias que proliferaram de um site ou blog de notícias para outro como um vírus, é realmente muito fácil erradicar completamente uma página da web ou várias páginas da web de todos os registros de existência - para remover essa página tanto para os mecanismos de pesquisa quanto para os a
Wayback Machine A nova máquina Wayback permite viajar visualmente de volta no tempo da InternetParece que desde o lançamento da Wayback Machine em 2001, os proprietários do site decidiram jogar fora o back-end baseado em Alexa e redesenha-lo com seu próprio código-fonte aberto. Depois de realizar testes com o ... consulte Mais informação . É claro que há um problema, mas vamos chegar a esse ponto.3 maneiras de remover páginas de blog da rede
O primeiro método é o usado pela maioria dos proprietários de sites, porque eles não conhecem melhor - simplesmente excluindo páginas da web. Isso pode acontecer porque você percebeu que possui conteúdo duplicado no site ou porque possui uma página que não deseja exibir nos resultados de pesquisa.
Simplesmente exclua a página
O problema com a exclusão total de páginas do seu site é que, já que você já estabeleceu a página no Na Internet, é provável que haja links de seu próprio site, bem como links externos de outros sites para esse determinado site. página. Quando você a exclui, o Google reconhece imediatamente essa sua página como uma página ausente.
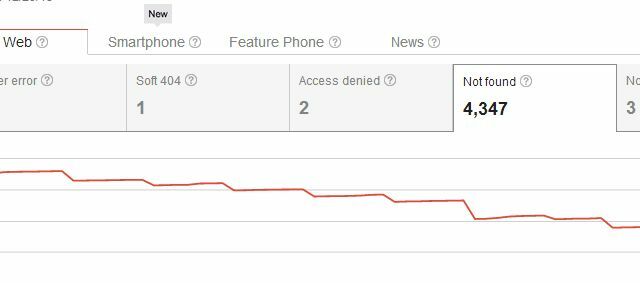
Portanto, ao excluir sua página, você não apenas criou um problema com os erros de rastreamento "Não encontrado", mas também criou um problema para qualquer pessoa que já vinculou à página. Geralmente, os usuários que acessam seu site a partir de um desses links externos verão sua página 404, que não é uma principal problema, se você usar algo como o código 404 personalizado do Google para fornecer aos usuários sugestões úteis ou alternativas. Mas você acha que poderia haver maneiras mais simples de excluir páginas dos resultados de pesquisa sem dar início a todos esses 404 para links de entrada existentes, certo?
Bem, existem.
Remover uma página dos resultados de pesquisa do Google
Antes de tudo, você deve entender que se a página da web que você deseja remover dos resultados de pesquisa do Google não for uma página do seu próprio site, você está sem sorte, a menos que haja razões legais ou se o site postou suas informações pessoais on-line sem o seu permissão. Se for esse o caso, use o Google solução de problemas de remoção para enviar uma solicitação para remover a página dos resultados da pesquisa. Se você tiver um caso válido, poderá encontrar algum sucesso ao remover a página - é claro que poderá ter um sucesso ainda maior apenas entrar em contato com o proprietário do site Como remover informações pessoais falsas na InternetA privacidade online não é mais garantida. Aprenda a denunciar um site e remover informações pessoais da Internet. consulte Mais informação como descrevi como fazer em 2009.
Agora, se a página que você deseja remover dos resultados da pesquisa estiver em seu próprio site, você está com sorte. Tudo que você precisa fazer é criar um robots.txt e certifique-se de que você não tenha permitido a página específica que você não deseja nos resultados da pesquisa ou o diretório inteiro com o conteúdo que você não deseja indexar. Veja como é o bloqueio de uma única página.
Agente de usuário: * Não permitir: /my-deleted-article-that-i-want-removed.html
Você pode impedir que os robôs rastreiem diretórios inteiros do seu site da seguinte maneira.
Agente de usuário: * Não permitir: / content-about-personal-stuff /
Google tem uma excelente página de suporte que pode ajudar a criar um arquivo robots.txt se você nunca criou um antes. Isso funciona muito bem, como expliquei recentemente em um artigo sobre estruturação de acordos de distribuição Como negociar acordos de distribuição e proteger seus rankings de pesquisaA distribuição é toda a raiva hoje em dia. Mas, de repente, você pode descobrir que o parceiro de organização está listado mais alto do que você nos resultados de pesquisa de uma história que você escreveu originalmente! Proteja seus rankings de pesquisa. consulte Mais informação para que eles não machucem você (solicite aos parceiros de distribuição que não permitam a indexação de suas páginas onde você está distribuído). Depois que meu próprio parceiro de organização concordou em fazer isso, as páginas que tinham conteúdo duplicado do meu blog desapareceram completamente das listagens de pesquisa.
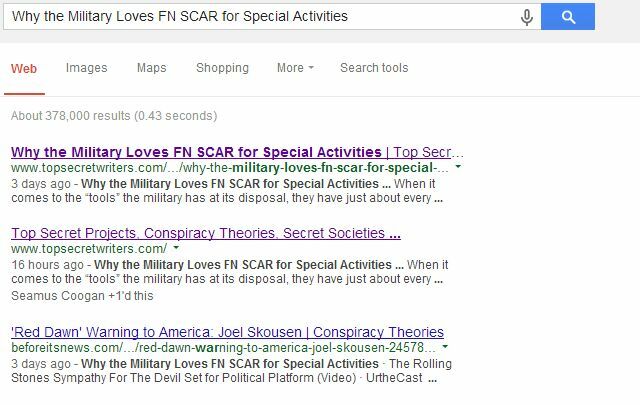
Somente o site principal aparece em terceiro lugar na página onde eles listam nosso título, mas meu blog agora está listado no primeiro e no segundo lugares; algo que seria quase impossível se um site de autoridade superior deixasse a página duplicada indexada.
O que muitas pessoas não percebem é que isso também é possível com o Internet Archive (o Wayback Machine) também. Aqui estão as linhas que você precisa adicionar ao seu arquivo robots.txt para que isso aconteça.
Agente do usuário: ia_archiver. Não permitir: / categoria-amostra /
Neste exemplo, estou dizendo ao Internet Archive para remover qualquer coisa do subdiretório de categoria de amostra no meu site da Wayback Machine. O arquivo da Internet explica como fazer isso na página de ajuda da Exclusão. É também aqui que eles explicam que "o Internet Archive não está interessado em oferecer acesso a sites ou outros documentos da Internet cujos autores não desejam seus materiais na coleção".
Isso contraria a crença comum de que qualquer coisa publicada na Internet é arrastada para o arquivo por toda a eternidade. Não. Os webmasters que possuem o conteúdo podem removê-lo especificamente do arquivo usando a abordagem robots.txt.
Remover uma página individual com meta tags
Se você possui apenas algumas páginas individuais que deseja remover dos resultados da Pesquisa Google, não precisa usar a abordagem robots.txt você pode simplesmente adicionar a metatag correta de “robôs” às páginas individuais e dizer aos robôs para não indexar ou seguir os links em toda a página. página.

Você pode usar a meta "robôs" acima para impedir que os robôs indexem a página ou informar especificamente o robô do Google não indexar para que a página seja removida apenas dos resultados de pesquisa do Google e outros robôs de pesquisa ainda possam acessar a página conteúdo.
Cabe a você decidir como deseja gerenciar o que os robôs fazem com a página e se a página é ou não listada. Para apenas algumas páginas individuais, essa pode ser a melhor abordagem. Para remover um diretório inteiro de conteúdo, siga o método robots.txt.
A idéia de "remover" conteúdo
Isso meio que vira toda a noção de "excluir conteúdo da Internet". Tecnicamente, se você remover todos os seus próprios links para uma página do seu site e removê-lo da Pesquisa Google e do Arquivo da Internet usando a técnica robots.txt, a página é para todos os efeitos "excluída" da Internet. O legal é que, se houver links para a página, esses links ainda funcionarão e você não acionará erros 404 para esses visitantes.
É uma abordagem mais "gentil" para remover o conteúdo da Internet sem prejudicar totalmente a popularidade dos links existentes no site em toda a Internet. No final, como você administra o conteúdo coletado pelos mecanismos de pesquisa e o Internet Archive depende de você, mas sempre lembre-se de que, apesar do que as pessoas dizem sobre a vida útil das coisas publicadas on-line, ela realmente está completamente dentro do seu ao controle.
Ryan é bacharel em Engenharia Elétrica. Ele trabalhou 13 anos em engenharia de automação, 5 anos em TI e agora é engenheiro de aplicativos. Um ex-editor-chefe do MakeUseOf, ele falou em conferências nacionais sobre visualização de dados e foi destaque na TV e rádio nacional.

