Propaganda
Se você administrar um site 10 maneiras de criar um site pequeno e simples sem exageroWordPress pode ser um exagero. Como esses outros serviços excelentes provam, o WordPress não é o começo e o fim de toda a criação de sites. Se você deseja soluções mais simples, há uma variedade para escolher. consulte Mais informação , provavelmente você já ouviu falar sobre um arquivo robots.txt (ou o “padrão de exclusão de robôs”). Quer tenha ou não, é hora de aprender sobre isso, porque este arquivo de texto simples é uma parte crucial do seu site. Pode parecer insignificante, mas você pode se surpreender com o quão importante é.
Vamos dar uma olhada no que é um arquivo robots.txt, o que ele faz e como configurá-lo corretamente para o seu site.
O que é um arquivo robots.txt?
Para entender como um arquivo robots.txt funciona, você precisa saber um pouco sobre os motores de busca Como funcionam os motores de busca?Para muitas pessoas, o Google é a Internet. É sem dúvida a invenção mais importante desde a própria Internet. E embora os mecanismos de pesquisa tenham mudado muito desde então, os princípios básicos ainda são os mesmos. consulte Mais informação . A versão resumida é que eles enviam “rastreadores”, que são programas que vasculham a Internet em busca de informações. Eles então armazenam algumas dessas informações para que possam direcionar as pessoas a elas mais tarde.
Esses rastreadores, também conhecidos como “bots” ou “spiders”, encontram páginas de bilhões de sites. Os mecanismos de pesquisa fornecem instruções sobre onde ir, mas sites individuais também podem se comunicar com os bots e dizer a eles quais páginas eles devem estar olhando.
Na maioria das vezes, eles estão realmente fazendo o oposto e dizendo em quais páginas eles não deveria estar olhando. Coisas como páginas administrativas, portais de back-end, páginas de categorias e tags e outras coisas que os proprietários de sites não desejam que sejam exibidas nos mecanismos de pesquisa. Essas páginas ainda estão visíveis para os usuários e podem ser acessadas por qualquer pessoa que tenha permissão (que geralmente é qualquer pessoa).
Mas, ao dizer a esses spiders para não indexarem algumas páginas, o arquivo robots.txt faz um favor a todos. Se você pesquisasse por “MakeUseOf” em um mecanismo de pesquisa, gostaria que nossas páginas administrativas aparecessem no topo das classificações? Não. Isso não faria bem a ninguém, por isso dizemos aos motores de pesquisa para não os apresentar. Ele também pode ser usado para impedir que os mecanismos de pesquisa verifiquem páginas que podem não ajudá-los a classificar seu site nos resultados da pesquisa.
Resumindo, o robots.txt diz aos rastreadores da web o que fazer.
Os rastreadores podem ignorar o robots.txt?
Os rastreadores sempre ignoram os arquivos robots.txt? sim. Na verdade, muitos rastreadores Faz ignore isto. Geralmente, no entanto, esses rastreadores não são de mecanismos de pesquisa confiáveis. Eles vêm de spammers, coletores de e-mail e outros tipos de bots automatizados Como construir um rastreador básico da web para obter informações de um siteSempre quis capturar informações de um site? Veja como escrever um rastreador para navegar em um site e extrair o que você precisa. consulte Mais informação que percorrem a internet. É importante manter isso em mente - usar o padrão de exclusão de robôs para dizer aos bots para se manterem afastados não é uma medida de segurança eficaz. Na verdade, alguns bots podem começar com as páginas que você diz a eles para não irem.
Os mecanismos de pesquisa, no entanto, farão o que seu arquivo robots.txt diz, desde que esteja formatado corretamente.
Como escrever um arquivo robots.txt
Existem algumas partes diferentes que entram em um arquivo padrão de exclusão de robô. Vou dividi-los individualmente aqui.
Declaração do agente do usuário
Antes de dizer a um bot quais páginas ele não deve olhar, você deve especificar com qual bot está falando. Na maioria das vezes, você usará uma declaração simples que significa "todos os bots". Isso se parece com isto:
Agente de usuário: *O asterisco significa "todos os bots". Você pode, no entanto, especificar páginas para certos bots. Para fazer isso, você precisa saber o nome do bot para o qual está definindo as diretrizes. Isso pode ser parecido com isto:
User-agent: Googlebot. [lista de páginas a não rastrear] User-agent: Googlebot-Image / 1.0. [lista de páginas a não rastrear] Agente do usuário: Bingbot. [lista de páginas a não rastrear]E assim por diante. Se você descobrir um bot que não deseja rastrear seu site, você também pode especificar isso.
Para encontrar os nomes dos agentes de usuário, verifique useragentstring.com [não mais disponível].
Não permitindo páginas
Esta é a parte principal do arquivo de exclusão do seu robô. Com uma declaração simples, você diz a um bot ou grupo de bots para não rastrear certas páginas. A sintaxe é fácil. Veja como você não permitiria o acesso a tudo no diretório “admin” do seu site:
Disallow: / admin /Essa linha evitaria que os bots rastreassem seusite.com/admin, seusite.com/admin/login, seusite.com/admin/files/secret.html e qualquer outra coisa que caia no diretório admin.
Para proibir uma única página, basta especificá-la na linha de proibição:
Disallow: /public/exception.htmlAgora, a página de “exceção” não será arrastada, mas todo o resto na pasta “pública” será.
Para incluir vários diretórios ou páginas, basta listá-los nas linhas subsequentes:
Disallow: / private / Disallow: / admin / Disallow: / cgi-bin / Disallow: / temp /Essas quatro linhas se aplicarão a qualquer agente de usuário especificado na parte superior da seção.
Se quiser evitar que os bots vejam qualquer página do seu site, use o seguinte:
Disallow: /Definindo Padrões Diferentes para Bots
Como vimos acima, você pode especificar certas páginas para diferentes bots. Combinando os dois elementos anteriores, fica assim:
User-agent: googlebot. Disallow: / admin / Disallow: / private / User-agent: bingbot. Disallow: / admin / Disallow: / private / Disallow: / secret /As seções “admin” e “privada” ficarão invisíveis no Google e no Bing, mas o Google verá o diretório “secreto”, enquanto o Bing não.
Você pode especificar regras gerais para todos os bots usando o agente de usuário asterisco e, em seguida, dar instruções específicas aos bots nas seções subsequentes também.
Juntando tudo
Com o conhecimento acima, você pode escrever um arquivo robots.txt completo. Basta abrir seu editor de texto favorito (estamos fãs de Sublime 11 dicas de texto sublime para produtividade e um fluxo de trabalho mais rápidoSublime Text é um editor de texto versátil e um padrão ouro para muitos programadores. Nossas dicas se concentram na codificação eficiente, mas os usuários em geral apreciarão os atalhos de teclado. consulte Mais informação por aqui) e comece a informar os bots de que eles não são bem-vindos em certas partes do seu site.
Se quiser ver um exemplo de arquivo robots.txt, basta acessar qualquer site e adicionar “/robots.txt” ao final. Esta é parte do arquivo robots.txt da Giant Bicycles:
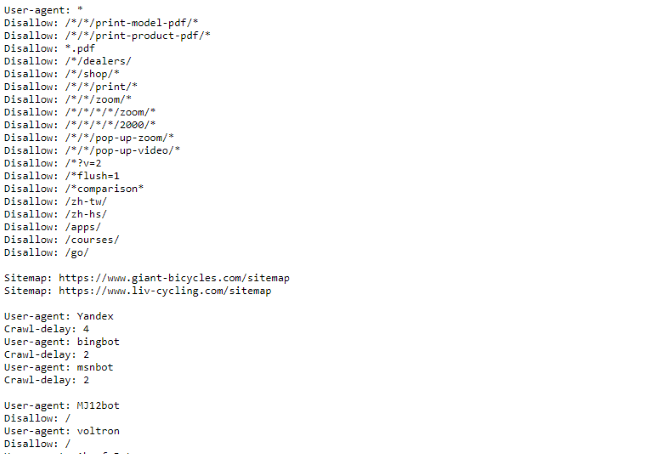
Como você pode ver, existem algumas páginas que eles não querem que apareçam nos mecanismos de pesquisa. Eles também incluíram algumas coisas sobre as quais ainda não conversamos. Vamos dar uma olhada no que mais você pode fazer em seu arquivo de exclusão de robô.
Localizando Seu Sitemap
Se o seu arquivo robots.txt informa aos bots onde não para ir, seu mapa do site faz o oposto Como criar um Sitemap XML em 4 etapas fáceisExistem dois tipos de sitemaps - página HTML ou arquivo XML. Um sitemap HTML é uma única página que mostra aos visitantes todas as páginas de um site e geralmente contém links para elas ... consulte Mais informação e os ajuda a encontrar o que procuram. E embora os mecanismos de pesquisa provavelmente já saibam onde está o seu sitemap, não faz mal deixá-los saber novamente.
A declaração de localização de um mapa do site é simples:
Mapa do site: [URL do mapa do site]É isso.
Em nosso próprio arquivo robots.txt, tem a seguinte aparência:
Mapa do site: //www.makeuseof.com/sitemap_index.xmlIsso é tudo que há para fazer.
Definir um atraso de rastreamento
A diretiva de atraso de rastreamento informa a certos mecanismos de pesquisa com que frequência eles podem indexar uma página em seu site. É medido em segundos, embora alguns mecanismos de pesquisa o interpretem de maneira um pouco diferente. Alguns veem um atraso de rastreamento de 5 como um aviso para aguardar cinco segundos após cada rastreamento para iniciar o próximo. Outros interpretam isso como uma instrução para rastrear apenas uma página a cada cinco segundos.
Por que você diria a um rastreador para não rastrear o máximo possível? Para preservar a largura de banda 4 maneiras pelas quais o Windows 10 está desperdiçando sua largura de banda da InternetO Windows 10 está desperdiçando sua largura de banda da Internet? Veja como verificar e o que você pode fazer para impedi-lo. consulte Mais informação . Se o seu servidor está lutando para acompanhar o tráfego, você pode querer instituir um atraso de rastreamento. Em geral, a maioria das pessoas não precisa se preocupar com isso. Sites grandes de alto tráfego, no entanto, podem querer experimentar um pouco.
Veja como você define um atraso de rastreamento de oito segundos:
Atraso de rastreamento: 8É isso. Nem todos os mecanismos de pesquisa obedecerão à sua diretiva. Mas não custa perguntar. Assim como ocorre com a não permissão de páginas, você pode definir diferentes atrasos de rastreamento para mecanismos de pesquisa específicos.
Enviando seu arquivo robots.txt
Depois de ter todas as instruções em seu arquivo configuradas, você pode carregá-lo em seu site. Certifique-se de que é um arquivo de texto simples e tem o nome robots.txt. Em seguida, carregue-o no seu site para que possa ser encontrado em yoursite.com/robots.txt.
Se você usar um sistema de gerenciamento de conteúdo 10 sistemas de gerenciamento de conteúdo online mais popularesOs dias das páginas HTML codificadas à mão e do domínio do CSS já se foram. Instale um sistema de gerenciamento de conteúdo (CMS) e em poucos minutos você pode ter um site para compartilhar com o mundo. consulte Mais informação como o WordPress, provavelmente há uma maneira específica de fazer isso. Por ser diferente em cada sistema de gerenciamento de conteúdo, você precisará consultar a documentação do seu sistema.
Alguns sistemas também podem ter interfaces online para enviar seu arquivo. Para isso, basta copiar e colar o arquivo criado nas etapas anteriores.
Lembre-se de atualizar seu arquivo
O último conselho que darei é, ocasionalmente, examinar seu arquivo de exclusão de robô. Seu site muda e você pode precisar fazer alguns ajustes. Se você notar uma mudança estranha no tráfego do seu mecanismo de pesquisa, é uma boa ideia verificar o arquivo também. Também é possível que a notação padrão mude no futuro. Como tudo o mais em seu site, vale a pena conferir de vez em quando.
De quais páginas você exclui os rastreadores do seu site? Você notou alguma diferença no tráfego do mecanismo de pesquisa? Compartilhe seus conselhos e comentários abaixo!
Dann é um consultor de marketing e estratégia de conteúdo que ajuda as empresas a gerar demanda e leads. Ele também bloga sobre estratégia e marketing de conteúdo em dannalbright.com.